埋了三年的大坑-LLM实例内存泄漏
年初八,上班第一天,"开门红",就问吓人不吓人。
别说了,赶紧重启下服务。然后叫上 claude code,排查!
现象
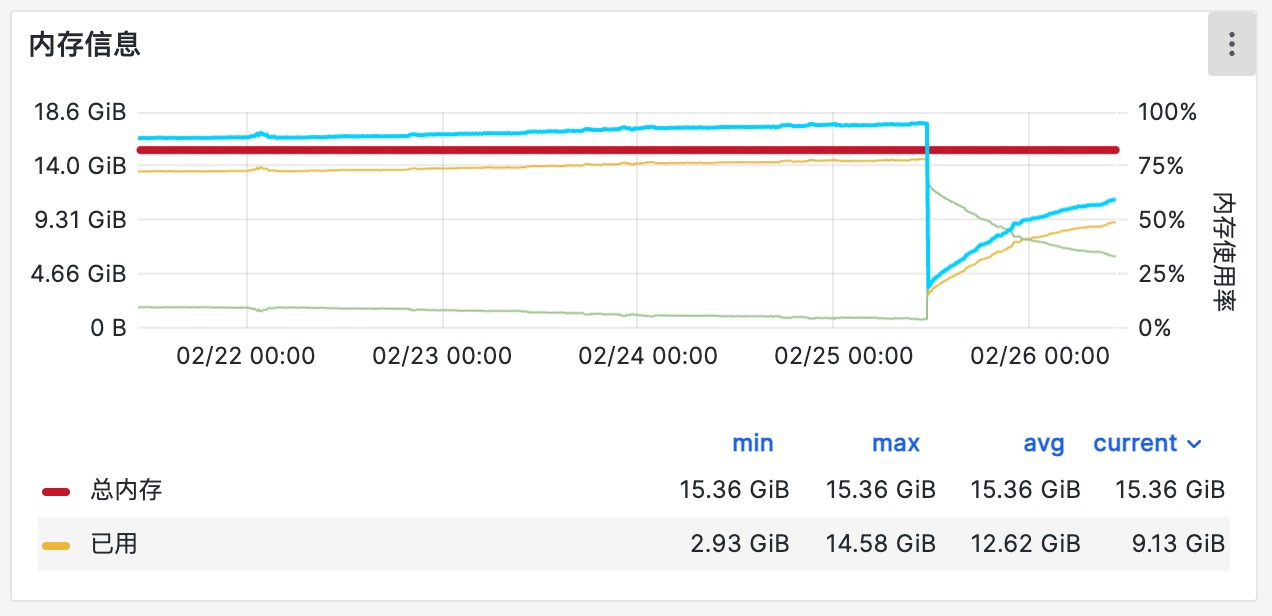
重启后,又跑了几个小时:
- 内存从 2.9G 迅速涨到 9.5G,还在快速上升,没有收敛迹象
- 同时,发现TCP 连接数跟着几乎同步在上涨
但当时很迷惑的一点是:同代码、同镜像,另一个项目内存几乎不涨。后来想到是流量低,gc回收速度比创建速度快。
定位
先让cc整体过一遍代码,看看有没有明显的内存泄漏点。初步发现了几个可疑点:
- nacos实例没有正确关闭
- langgraph service非单例模式,在重复创建
- llm client/boto3等在重复创建
然后让cc写了段 tracemalloc 代码,重新部署到了线上。(小公司,研发都得兼职一部分运维的活)
临时加了个 debug 接口,在运行中打开追踪:
import tracemalloc
tracemalloc.start(25)
snapshot = tracemalloc.take_snapshot()
for stat in snapshot.statistics("lineno")[:20]:
print(stat)几轮采样下来,热点基本稳定在几类位置:
openai/_client.py一直在分配botocore/model.py也在涨- 一些
functools相关对象数量很夸张
这就很像“客户端反复创建、连接池重复初始化”这一类问题,而不是单纯某个 list 忘了清。
根因:工厂函数每次都 new 客户端
最后定位到公共工厂函数,逻辑非常朴素,也非常致命:
def get_llm(model_id, **kwargs):
config = config_center.get(model_id)
params = config.to_dict()
return init_chat_model(**params) # 每次调用都创建新实例问题在于:
- 部分LLM client 内部会持有
httpx.AsyncClient - 部分云厂商 client 内部会持有连接相关资源
如果一次请求里要调用 5-10 次模型,那就是 5-10 套资源在初始化。你说它完全不回收吧,也不是;但它回收速度明显跟不上创建速度,这个就很要m命。
为啥 GC 顶不住
gc.collect() 回收的是 Python 对象引用,不等价于“底层连接立刻干净释放”。
异步客户端通常要显式 await aclose() 才会及时把资源还回去,而你靠 __del__ 去兜底,基本就是看运气。
一句话:对象没了,不代表 socket 立刻没了。画重点,要牢记!
修法一:按参数做 LRU 复用
既然配置组合就那么几十种,那就别每次都建新实例了,直接按参数缓存。
from collections import OrderedDict
from threading import RLock
_CACHE_SIZE = int(os.environ.get("LLM_CACHE_SIZE", "128"))
_cache: OrderedDict[str, BaseChatModel] = OrderedDict()
_cache_lock = RLock()
def get_llm(model_id, **kwargs):
config = config_center.get(model_id)
params = config.to_dict()
if _CACHE_SIZE <= 0:
return init_chat_model(**params) # 0 或负数表示禁用缓存
cache_key = json.dumps(params, sort_keys=True, default=str)
with _cache_lock:
cached = _cache.get(cache_key)
if cached is not None:
_cache.move_to_end(cache_key)
return cached
llm = init_chat_model(**params)
_cache[cache_key] = llm
_cache.move_to_end(cache_key)
while len(_cache) > _CACHE_SIZE:
_cache.popitem(last=False)
return llmLLM_CACHE_SIZE=0明确语义为“禁用缓存”check-create-store放在同一把锁里,避免并发 miss 时重复创建- 配置中心更新后参数会变,key 自然变化,旧实例等 LRU 淘汰
修法二:处理缓存后的 mutation 污染
(一开始没想到,是让cc 和 codex相互review后发现的。惊喜!)
缓存加完不是结束,才刚开始。
之前每次返回新实例,调用方随手改属性问题不大;现在实例共享了,再改就会串请求。
典型反面教材:
llm = get_llm(model_id)
llm.model_kwargs["extra_headers"] = {"X-Request-ID": req_id} # 共享对象被污染处理方式是“共享底层连接,隔离请求态字段”:
llm = llm.model_copy(update={
"model_kwargs": {**llm.model_kwargs, "extra_headers": {"X-Request-ID": req_id}}
})这样连接池不会重新建,但请求级字段不会互相污染。性能损耗可接受,语义也干净很多。
低流量实例为什么看起来正常
因为这个 bug 不是“马上炸”,而是“慢性失血”。
可以粗暴理解成:泄漏速率 = 创建速率 - 释放速率
低流量下,这个值可能接近 0,看着像没事;高流量一上来,差值变大,就开始稳步爬生。不是它今天突然变坏了,是你终于把它喂饱了。
验证结果
修完上线后,重点观察了几个指标:
- 新建 LLM 实例日志只在冷启动阶段出现少量,随后基本命中缓存
openai/_client.py、botocore/model.py对应分配显著下降- 进程 RSS 不再线性上涨,TCP 连接数趋于稳定
终于不再靠“定时重启保平安”这种祖传手艺续命了。
复盘(划重点)
这类问题本质上是老三样:
- 资源工厂没复用
- 生命周期管理靠玄学
- 高流量把隐患放大
划重点:
- 异步资源尽量显式管理生命周期,别把希望全压在 GC 身上
- 缓存上线前,先全局扫一遍 mutation 点,不然很容易引入“共享状态污染”
tracemalloc好用- 低流量“没复现”只能说明压不出来,不能说明没问提
这次 vibe coding 真的挺🐂🍺,它能很快把大范围线索捞出来,然后配合部分人工的介入,定位修复还挺快。