Langgraph Checkpointer底层原理
国庆回来后,就all in到Agentic chatflow的开发中的(还把人拉到外地去集中办公,累死人啦啊啊啊)
然后看到langgraph出1.0版本了,正好也趁这个机会(恰好也有和同事做技术分享),就看下checkpointer的底层原理。(之前只是知道怎么用,但不太清楚原理)
核心概念
LangGraph 内置了持久层,通过 Checkpoint 实现。当编译 graph 时传入 checkpointer,它会在每个 Super Step 处保存一份 graph state 的 checkpoint,这些 checkpoint 会关联到对应的 thread。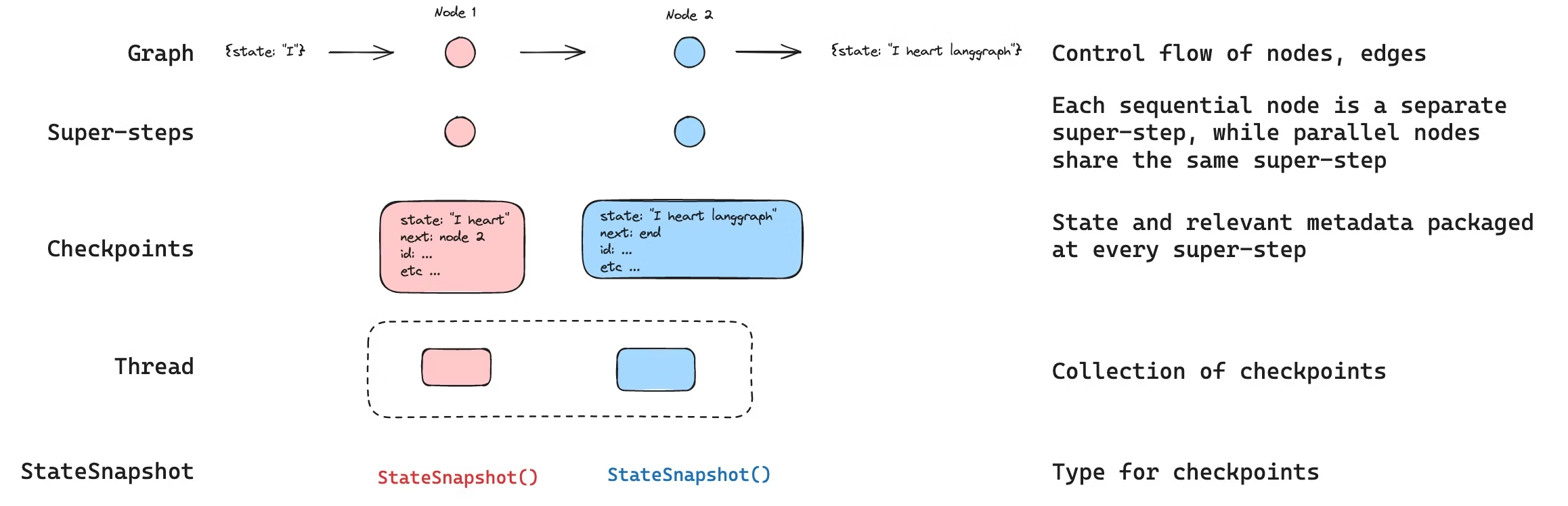
- Thread ID <=> Session ID、Chat ID
- Checkpoint <=> Snapshot
使用 checkpointer 时必须传入的唯一配置就是:
{"configurable": {"thread_id": "1"}}Checkpoint 数据结构
在 Graph API 层面表现为 StateSnapshot:
class StateSnapshot(NamedTuple):
values: dict[str, Any] | Any # 当前 channel 值
next: tuple[str, ...] # 下一步要执行的节点
config: RunnableConfig # 配置
metadata: CheckpointMetadata | None # 元数据
created_at: str | None # 创建时间
parent_config: RunnableConfig | None # 父 checkpoint 配置
tasks: tuple[PregelTask, ...] # 待执行任务
interrupts: tuple[Interrupt, ...] # 待处理中断关键点:在非并行情况下,checkpoint 会在每个node执行之前创建,然后在node执行之后更新。
有了 checkpoint,LangGraph 才能支持这些高级特性:
- Human-in-the-loop:人类可随时查看/修改状态
- Memory:记忆能力
- Time Travel:重放特定步骤,从任意 checkpoint 分叉
- Fault-tolerance:从上一个 SuperStep 重新执行
- Pending writes:不重新运行已成功的节点
Pregel Model
官方文档:LangGraph Pregel
LangGraph 底层使用 Pregel 作为运行基础,取名源自 Google 的经典图计算框架最早是为大规模图计算(如 PageRank、广度优先搜索等)设计的,核心思想是:
Think Like a Vertex
每个顶点是独立的计算单元(actor),顶点之间通过有向边(channel)通信。整个计算由一系列 Super Step 组成:
- Plan:决定哪些 actor 将执行
- Execution:所有 actor 并行执行,互相看不到对方的计算过程
- Update:根据执行结果更新对应的 channel
重复执行直到没有 actor 被选中或达到循环上限。
Pregel Channel
Graph API 和 Functional API 构建的 graph 最终都会编译为 Pregel 对象。核心是 PregelNode(也叫Actor,有点像LangChain 的 Runnable 类似) 和 BaseChannel。
LangGraph 提供的 channel 类型:(可能不太全?)
- LastValue:存储最新值,每个 superstep 只能收到 1 个值
- Topic:PubSub Topic,可接收多值,广播给多接收者
- BinaryOperatorAggregate:存储一个持久值,通过将二元运算符应用于当前值和发送到通道的每个更新来更新该值,适用于在多个步骤中计算聚合
举个例子,假设有这样的 State:
class MessagesState(TypedDict):
messages: Annotated[list[AnyMessage], add_messages]
class ChatFlowState(MessagesState):
node_results: List[NodeExecutionResult]
current_node_name: Optional[str]
execution_path: List[str]
extra_info: Optional[StateExtraInfo]编译后的 channels:
{
'messages': BinaryOperatorAggregate, # 因为有 Annotated
'node_results': LastValue,
'current_node_name': LastValue,
'execution_path': LastValue,
'extra_info': LastValue,
'__start__': EphemeralValue,
'__pregel_tasks': Topic,
'branch:to:xxx': EphemeralValue, # 各节点的分支
}⚠️ 踩坑提醒:LangGraph 不会解析嵌套的 Annotated 字段!
class SubState(TypedDict):
cnt: Annotated[int, operator.add] # 这个不会生效!
res: Annotated[str, operator.concat] # 这个也不会!
class State(TypedDict):
sub_state: SubState # 整个会被当作 LastValue实测 sub_state 内部的累加和拼接完全不起作用。
持久化模式
三种持久化模式:
- exit:仅当 graph 执行完成(成功/错误/interrupt)时才保存
- async:执行过程中异步提交
- sync:执行过程中同步提交
序列化:默认使用 JsonPlusSerializer(底层是 ormsgpack,Rust 实现,性能很强)
CheckpointSaver
所有 checkpoint 持久化操作封装在 BaseCheckpointSaver:
| 方法 | 功能 |
|---|---|
.put | 写入 checkpoint |
.put_writes | 写入中间结果(pending writes) |
.get_tuple | 获取 checkpoint tuple(graph.get_state() 底层) |
.list | 批量查询(graph.get_state_history() 底层) |
.delete_thread | 删除 thread 关联的所有 checkpoints |
PostgresSaver 存储结构
PostgresSaver 使用三张核心表:
checkpoints 表:每个 checkpoint 一条记录
CREATE TABLE "checkpoints" (
"thread_id" text NOT NULL,
"checkpoint_ns" text NOT NULL DEFAULT '',
"checkpoint_id" text NOT NULL,
"parent_checkpoint_id" text,
"type" text,
"checkpoint" jsonb NOT NULL,
"metadata" jsonb NOT NULL DEFAULT '{}',
PRIMARY KEY ("thread_id", "checkpoint_ns", "checkpoint_id")
);checkpoint_blobs 表:非基础类型值序列化存储
CREATE TABLE "checkpoint_blobs" (
"thread_id" text NOT NULL,
"checkpoint_ns" text NOT NULL DEFAULT '',
"channel" text NOT NULL,
"version" text NOT NULL,
"type" text NOT NULL,
"blob" bytea,
PRIMARY KEY ("thread_id", "checkpoint_ns", "channel", "version")
);checkpoint_writes 表:运行时 channel 中间数据
CREATE TABLE "checkpoint_writes" (
"thread_id" text NOT NULL,
"checkpoint_ns" text NOT NULL DEFAULT '',
"checkpoint_id" text NOT NULL,
"task_id" text NOT NULL,
"idx" int4 NOT NULL,
"channel" text NOT NULL,
"type" text,
"blob" bytea NOT NULL,
"task_path" text NOT NULL DEFAULT '',
PRIMARY KEY ("thread_id", "checkpoint_ns", "checkpoint_id", "task_id", "idx")
);实测对比
用一个简单的图测试:START → node_a → node_user(interrupt) → node_b → node_end
async 模式(执行到 interrupt):
- checkpoints 表:3 条记录
- checkpoint_blobs 表:3 条记录
- checkpoint_writes 表:7 条记录
exit 模式(执行到 interrupt):
- checkpoints 表:1 条记录
- checkpoint_blobs 表:1 条记录
- checkpoint_writes 表:1 条记录(仅 interrupt)
差距还是很明显的!
总结
- LangGraph 只解析 StateSchema 第一层,嵌套的 Annotated 不起作用
compile()操作将图解析成 Pregel 构建的图- StateSchema 第一层字段都会被解析为 channel
- 每个 SuperStep 会并发处理当前轮次操作(但我们目前没有并行场景)
- 使用 GraphAPI 时,进入 START 节点和用户定义节点之前会生成 checkpoint
- 非基础类型字段序列化后存
checkpoint_blobs,基础字段直接存checkpoints - SuperStep 执行中每个 channel 写入会保存到
checkpoint_writes - exit 模式写入次数大幅下降,代价是无法从中间状态恢复
- 极致优化应减少 State 字段数量,控制写入数据量
- PostgreSQL 性能很强,存的都是 byte/jsonb 高效格式